

如今的视觉 AI 模型面临着动态的复杂环境,因此,在实时应用中,必须提高能效和速度。
为了满足市场需求,瑞萨电子推出了新一代 DRP-AI 加速器。 DRP-AI 加速器的能效高达 10 TOPS/W,高出传统技术 10 倍,不仅能够运行此前需要使用 GPU 的复杂图像 AI 模型,而且功耗低至与传统嵌入式 MPU 相当。
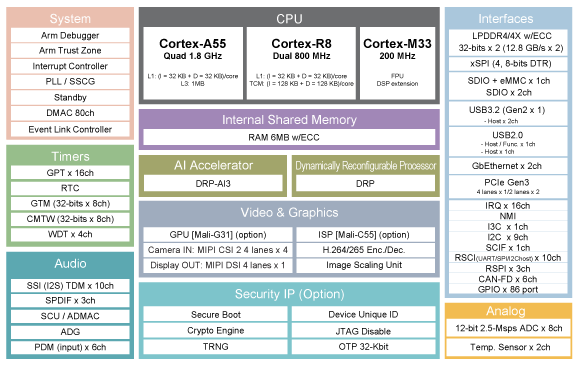
除了这个AI 加速器之外,高端 RZ/V2H 微处理器 (MPU) 还配备了使用动态可配置处理器 (DRP)的图像处理加速器、运行频率高达 1.8 GHz 的四核 Linux 处理器 Arm® Cortex®-A55、双核800MHz Arm Cortex-R8高速实时处理器以及I/O 处理用的子核 Arm Cortex-M33,采用异构多处理器配置。
7个基于Arm 的 CPU内核、新一代 DRP-AI 和 DRP 的组合,能够立即处理机械控制中的图像识别和 AI 判断结果,使其成为新一代自主机器人、自主移动机器人、无人机和其他应用的理想 AI 处理器。 阅读本博客,详细了解这款新产品的特性。
新一代 AI 加速器 DRP-AI
RZ/V2M、RZ/V2L 和 RZ/V2MA 中已嵌入瑞萨电子自研的 DRP-AI 加速器,同时,瑞萨电子也将独创的 AI 处理器 DRP-AI 升级到新一代,以便满足新的市场需求。
为了大幅提升电源效率,DRP-AI 采用了 INT8 量化技术和硬件支持,以便进行非结构化剪枝,这是传统 AI 加速器难以实现的,由此实现了高达 80 TOPS 的推理性能以及 10 TOPS/W 的电源效率。 阅读本白皮书,了解更多关于非结构化剪枝的信息。
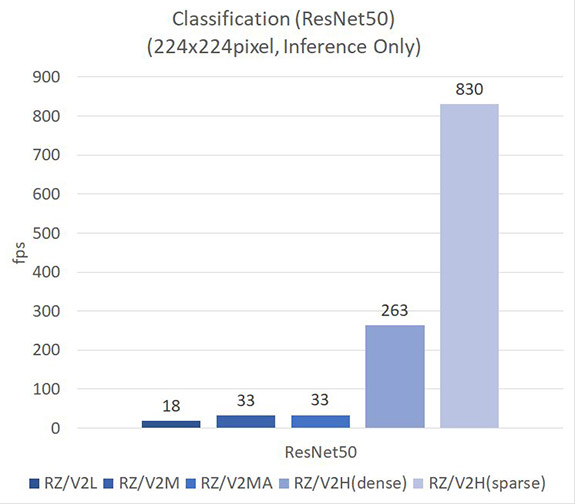
下图 1 展示了不同 RZ/V 产品之间的 AI 推理性能比较。 对于常见的 CNN 类型——Resnet50,在未剪枝时(密集模型),其性能高出 RZ/V2L 14 倍,而剪枝后则高出 45 倍。
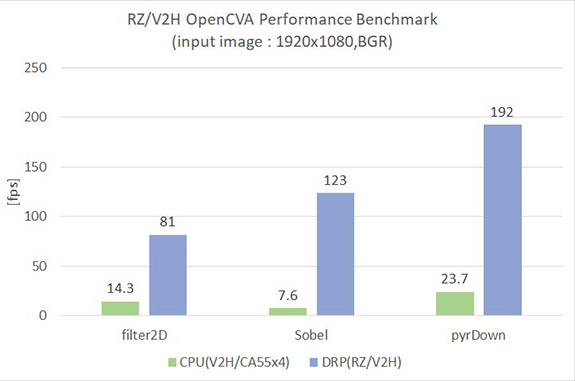
动态可配置处理器 DRP 助力 OpenCV 加速器
早在深度学习问世之前,图像识别和决策应用就用到了各种方法。 开源计算机视觉库 OpenCV 就是其中的一个例子。 即使是在 AI 图像处理已经成为现实的今天,OpenCV 仍然是一项非常实用的技术。 在合适的情况下,如今可以将视觉 AI 和 OpenCV 搭配使用。
为了加速 AI 和各种图像处理算法(例如 OpenCV),RZ/V2H MPU 的设计采用了与 DRP-AI 分离的动态可配置处理器,以便为 OpenCV 加速器提供 DRP 库,充分发挥它的灵活优势。
下方的图 2 将带有 DRP 的 OpenCV 加速器与 RZ/V2H 四核 CPU 的性能进行了对比。 例如,使用 DRP 加速后,用于图像边缘检测的 Sobel 滤波器的速度提高了 16 倍,从 7.6 fps 提升到 123 fps。
AI 异构配置 + 高速实时控制
尽管高速多核 Linux 处理器是图像 AI 的理想之选,但它需要庞大的内存资源,并且难以实现机械控制所需的亚毫秒级实时性能。
为了解决这一问题,RZ/V2H 采用了四核 Cortex-A55 来运行 Linux 程序(包括 AI 处理在内),并针对需要高速实时性能的应用(例如电机控制),采用了专用的高速实时处理器进行 RTOS 处理。
借助 OpenAMP,通过处理器间的通信将这些不同的操作系统相连后,DRP-AI 和 Linux 处理器的决策结果可以由 RTOS 处理器实时反映在机械控制中。
具备这些独特特性的 RZ/V2H 嵌入式 AI 微处理器已投入量产,而 RZ/V2H 评估板也已准备就绪,随时可以帮助您开启下一个视觉 AI 开发项目。
请访问 www.renesas.com/rzv2h,了解更多有关 RZ/V2H MPU 的信息, 并且探索既可以作为系统模块 (SOM) 实现开发可扩展性,又可以作为应用驱动型单板计算机 (SBC) 解决方案实施的视觉检测单板计算机。