
为什么选择边缘 AI?
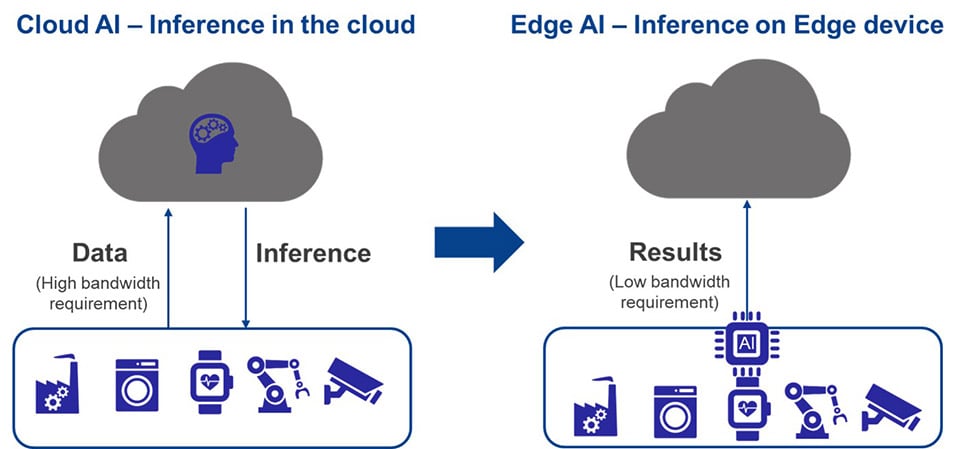
AI 市场已经发生了根本性变革。 过去,AI 处理主要在云端完成。 End Point 设备从传感器收集数据并将其发送到云端进行推理处理和决策,结果被发送回 End Point 设备。 这种方法需要巨大的带宽才能将海量数据传输到云端。 IDC 估计,到 2025 年,将有 79.4ZB 的数据从 IoT 设备发送到云端。
边缘设备越来越多地使用 AI 推理技术,以实现快速实时响应并提高数据隐私和安全性,同时避免与云连接产生的延迟和成本。 这也降低了功耗,使其适用于电池供电的 IoT 应用。 因此,边缘 AI 具有自主性、低延迟、低功耗、低成本、更低的云端带宽、安全性更高的优势,这使其对新兴应用具有吸引力。
MCU 越来越多地用于边缘 AI。 与 MPU 相比,它们提供更好的实时响应、更低的功耗、更低的成本,以及简化产品设计并降低开发和 BOM 成本的全面集成解决方案,使其成为低功耗和成本经济型应用的理想选择。 现已推出具有集成硬件加速器的高性能 MCU,可以处理神经网络处理所需的线性代数运算,例如点积和快速、并行矩阵乘法、卷积和转置。 此外,还提供针对资源有限的 MCU 而优化的小型神经网络模型、软件库和生态系统解决方案。
使用 RA8P1 AI 加速 MCU 构建高能效 AI 应用
RA8P1 MCU 是瑞萨电子首款 AI 加速的单核和双核 MCU,具有高性能 Arm® Cortex-M85® (CM85) 和 Cortex-M33 (CM33) CPU 内核以及 Arm Ethos TM-U55 神经网络处理器 (NPU),是边缘 AI 和物联网应用的理想选择,可在 AI/ML、DSP 和标量性能方面提供更大的提升和更低的功耗。 RA8P1 MCU 基于先进的台积电 22nmULL 工艺构建,提供前所未有的 7300+ CoreMark 原始性能和 256 GOPS 的 AI 性能,并满足了边缘 AI 应用对低功耗的需求。
这类MCU与大内存和丰富的外设集相结合,可以直接在MCU本身上实现要求苛刻的语音、视觉 AI 和实时分析应用程序。 双核 RA8P1 MCU 可实现高处理能力、两个内核之间的高效任务划分以及优化的实时性能。 此外,还内置了高级安全性、不可变内存和 TrustZone,以实现真正安全的 AI 应用程序。
RA8P1 中嵌入的 Ethos-U55 NPU 是一款专用处理器,经过优化,可与 CPU 内核更高效、更低功耗地执行神经网络模型的核心运算,例如矩阵乘法和卷积。 Ethos-U55 针对 AI 模型中使用的低精度算术(8 位整数)进行了优化,可在不降低推理精度的情况下降低复杂性、内存使用和功耗。
瑞萨电子已经成功地展示了使用 Ethos-U55 进行推理处理的 RA8P1 MCU 的性能提升,并在一些 AI/ML 用例中展示了 Ethos-U55 NPU 与 CPU 内核相比的显著性能提升。
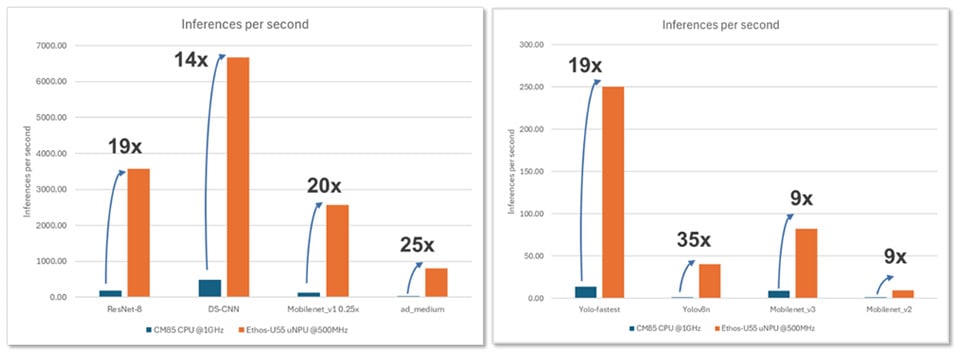
使用的型号:
- 图像分类 – ResNet8、MobileNet v2、MobileNet v3
- 关键词识别 – DS-CNN
- 视觉唤醒词 – MobileNet v1
- 对象检测 – Yolo_fastest、Yolov8N
- 异常检测 – ad_medium
使用 RUHMI 框架实现更快的应用程序开发
RA8P1 AI 解决方案采用高度可配置和优化的 RUHMI 框架,为 AI 开发人员提供更快、更高效的 AI 开发所需的所有工具。 这是瑞萨电子第一个用于 MCU 和 MPU 的综合 AI 框架,并集成到 e2 中,以与框架无关的方式生成和部署高度优化的神经网络模型。 RUHMI 支持模型优化、量化、图形编译和转换为 MCU 友好格式。 包括对常用 ML 框架 TensorFlow Lite、Pytorch 和 ONNX 的原生支持,以及针对 RA8P1 优化的即用型应用程序示例和模型。
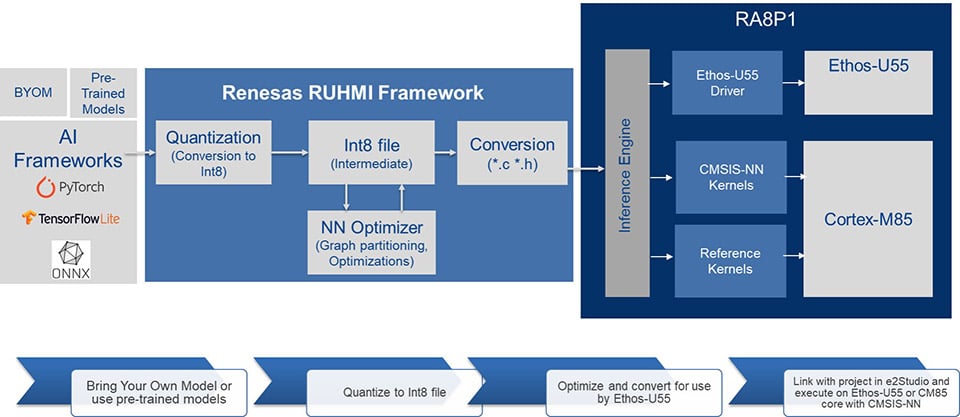
T使用 RUHMI 框架的典型 AI 工作流程:
- 模型优化和编译(离线): 预先训练的 AI 模型通过 Tensorflow Lite、Pytorch 或 ONNX 等常用框架输入。 使用 RUHMI 优化和转换工具,首先将模型量化为 Int8 中间格式并进行优化。 此过程涉及图形分区、在 NPU 和 CPU 之间分离运算符,以及编译为 MCU 友好格式(通常为 *.c/*.h)。
- 数据输入和预处理: RA8P1 MCU 捕获原始输入数据(来自摄像头的图像、来自麦克风的音频),并由高性能 Cortex-M85 内核进行预处理,以输入到 AI 模型。
- 在 NPU 上执行: 然后,CPU 内核将预处理后的输入数据和编译后的 AI 模型的命令流发送到 Ethos-U55 NPU 执行。 NPU 读取命令流,并使用输入数据和模型权重(通常存储在本地内存中)处理神经网络的每一层。
- 输出和后处理: 一旦 NPU 处理完神经网络的所有层,它就会将推理结果输出回主 CPU,然后主 CPU 可以执行任何必要的后处理和操作。
RA8P1 支持的 AI 应用
RA8P1 MCU 具有高推理性能、低功耗和实时处理能力,是各个细分市场的不同 AI 应用的理想选择。 以下是 RA8P1 支持的一些关键应用程序:
- 语音人工智能 – 关键词识别、语音识别、语速识别、降噪、发音人识别
- 视觉 AI – 目标检测、图像分类、手势识别、人脸识别、图像分析、驾驶员/车辆监控
- 实时分析 – 异常检测、振动分析、预测性维护
- 多模式应用 – 具有语音和视觉功能的智能 HMI、使用语音和视觉检测事件的增强型监控摄像头、具有视觉和听觉输入的机器人技术,用于环境传感和交互
在下一节中,我们来看看 RA8P1 如何通过两个应用示例帮助简化 AI 实现。
应用示例 1:RA8P1 上的图像分类
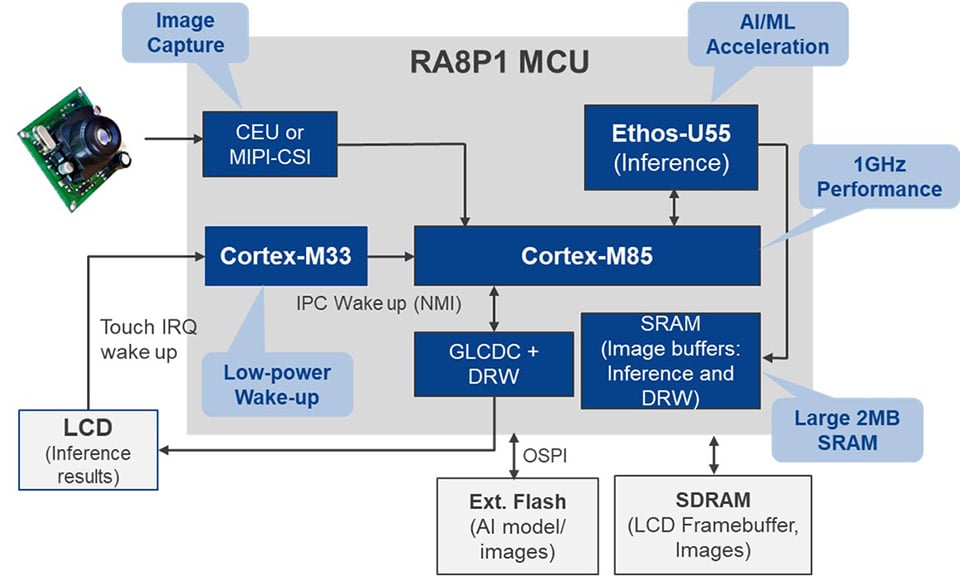
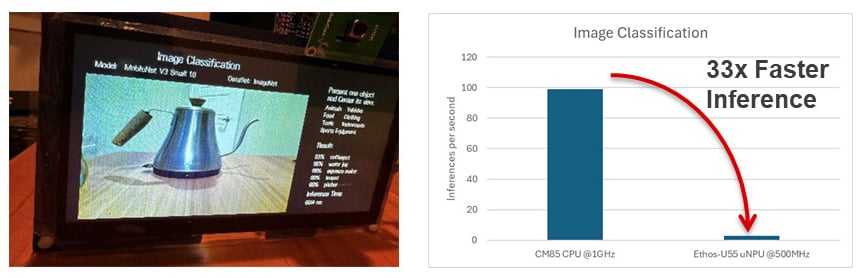
上图显示了图像分类应用程序实现。 RA8P1 将构建此视觉 AI 应用程序所需的 CPU 内核、NPU、内存和外设集成在单个芯片上。 应用程序会分析输入图像并为其分配预先分配的标签或类别。 神经网络模型在庞大的图像数据集上进行训练(其中每张图像都标有类别),并部署在 RA8P1 MCU 上。 为了进行推理,将新的输入图像输入到模型中,并通过经过训练的网络的各层。 然后,输出层提供所有类别的概率分布,并将概率最高的类别分配为图像的标签。 然后,可以将此输出数据(图像标签和准确性)发送到显示器或云。 在我们的实施中,我们看到与使用 CPU 内核相比,使用 Ethos-U55 的推理速度提高了 33 倍。
图像分类可用于各种应用:
- 安全 – 危险品识别、人员识别、异常检测
- 零售 – 按类别创建产品目录、库存管理
- 农业 – 识别作物病害、植物分类
- 智慧城市 – 识别交通信号灯/标志和行人
- 智能电器 – 识别冰箱内的物体
应用示例 2:RA8P1 上的驾驶员监控系统
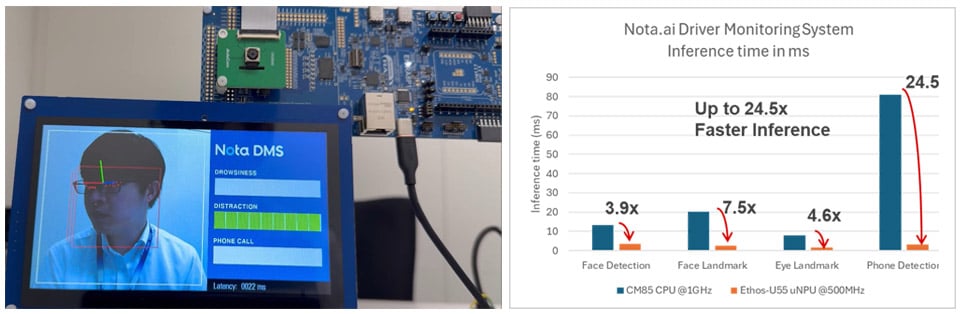
此应用程序展示了 Nota-AI 驾驶员监控系统 (DMS),这是一种车内安全解决方案,旨在增强车辆行驶各个方面的道路安全。 使用 RA8P1,Nota-ai DMS 可以检测未注册的驾驶员、驾驶员疲劳、手机使用情况以及驾驶员分心(如吸烟)的情况。
随着 RA8P1 的更高性能,我们看到该应用中使用的四种模型(人脸检测、人脸特征点、眼睛特征点和手机检测)的推理性能提高了 4 到 24 倍。
DMS 可用于仪表板摄像头、车辆行驶数据记录仪和驾驶员监控系统。
这两个视觉 AI 应用程序都充分利用了 RA8P1 MCU 上的资源:
- 通过图像传感器进行高效的输入图像采集:
- RA8P1 包括一个专用的 MIPI CSI-2 接口,带有图像缩放单元或 16 位 CEU 并行摄像头接口 ,用于捕获原始图像输入数据。
- 使用 Ethos-U55 NPU 进行高性能推理处理:
- RA8P1 MCU 上的 Ethos-U55 AI 加速器可分担 CPU 内核工作,并比 CPU 内核更高效、更低功耗地处理复杂的 AI 模型。 它从 MIPI CSI-2 或并行 CEU 接收处理后的图像。
- 预先训练的 AI 模型(例如,像 MobileNetv1 这样的图像分类模型)使用 RUHMI 工具针对 RA8P1 进行了优化,并加载到 NPU 上。
- Ethos-U55 NPU 以非常高的速度(高达 256 GOPS)和高功效执行实际的 AI 推理。
- 使用 Arm Cortex-M85 和 Cortex-M33 加快应用程序处理速度:
- 带有 Arm Helium 矢量扩展的高性能 1GHz CM85 内核 可用于输入图像或音频数据以及推理结果的预处理和后处理。 Ethos-U55 不支持的运算符也可以由 CM85 内核在回退模式下执行,由 CMSIS-NN 库加速。 它还用于执行应用程序代码。
- 250MHz Cortex-M33 内核 可用于低功耗唤醒和内务管理任务。
- 通过片上存储器和存储器接口高效存储图像、模型权重和激活:
- 片上 大型 1MB MRAM 和 2 MB SRAM 对于存储 AI 模型权重、图像和中间激活至关重要。 与闪存相比,集成的嵌入式 MRAM 具有更快的写入速度、更高的耐用性和数据保持率等优势。
- MCU 还支持适用于更大模型的 高吞吐量外部存储器接口 (具有 XIP 和动态解密的 OSPI 以及 32 位 SDRAM)。
- 用于 LCD 面板的 高级图形外设:
- GLCDC(具有并行 RGB 或 MIPI DSI 接口)和 2D 引擎可用于处理图像和推理结果并将其渲染到 LCD 显示器上。
- 灵活的连接选项:
- 存在多种连接选项,可将推理结果、图像或警报/通知传输到本地设备或云,以进行存储或分析。
边缘 AI 应用从 AI 加速 MCU 的使用中受益匪浅。 它们在实时性、低功耗和安全性重要的应用场景具有关键价值。 低功耗 MCU 的加入是 AI 解决方案领域的一个变革性变化。 全新 RA8P1 MCU 大幅降低延迟,实现数据隐私并最大限度地降低功耗,使其成为电池供电应用的理想选择。整个开发由瑞萨电子的全面 RUHMI 框架提供支持,该框架可帮助开发人员在 RA8P1 硬件上高效优化和部署其 AI 模型。
有关更多信息,请访问 www.renesas.com/ra8p1


